[Google DeepMind] - Tìm hiểu sâu về phân đoạn hình ảnh y tế với mã tương tác

Matthew Lai là một kỹ sư nghiên cứu tại Deep Mind, và anh ta cũng là người tạo ra hươu cao cổ, sử dụng phương pháp học tập tăng cường sâu để chơi cờ vua . Nhưng Master Msc Project của anh ấy là trên các hình ảnh MRI, đó là Học sâu về phân đoạn hình ảnh y tế , vì vậy tôi muốn xem xét sâu về dự án của anh ấy.
Và vì, đây không phải là một bài báo hội nghị truyền thống, mà là một Dự án tổng thể, tôi sẽ tiếp cận điều này một cách khác biệt. Tôi sẽ thực hiện Tóm tắt trên giấy (Ghi chú về những thứ tôi không biết) và Thực hiện.
Xin lưu ý rằng trong tài liệu gốc Matthew đã sử dụng bộ dữ liệu MRI của ADNI Alzheimer, rất tiếc là tôi không có quyền truy cập vào dữ liệu đó nên tôi sẽ sử dụng hình ảnh DRIVE: Hình ảnh võng mạc kỹ thuật số cho bộ dữ liệu trích xuất tàu . Ngoài ra, xin lưu ý do sử dụng một bộ dữ liệu khác nhau, cũng như các hạn chế về phần cứng, có một số khác biệt về kiến trúc mạng so với giấy gốc, tuy nhiên tôi đã cố gắng giữ cấu trúc chung tương tự.
2.2 Các nút mạng và chức năng kích hoạt


Ở đây tôi đã học được rằng có ba tiêu chí mà chức năng kích hoạt phải đáp ứng. (Tôi chỉ biết hai trong số họ.) Và đó là những khác biệt, phi tuyến tính và đơn điệu. (Tôi không biết về đơn điệu.)
Vi sai → Để thực hiện Tuyên truyền ngược
phi tuyến tính → Để cung cấp cho mô hình sức mạnh để tính toán hàm phi tuyến tính
Đơn điệu → Để ngăn không tạo thêm tối thiểu cục bộ
phi tuyến tính → Để cung cấp cho mô hình sức mạnh để tính toán hàm phi tuyến tính
Đơn điệu → Để ngăn không tạo thêm tối thiểu cục bộ
Hình ảnh bên trái → Một chức năng đang tăng đơn điệu
Hình ảnh trung bình → Một chức năng đang giảm đơn điệu
Hình ảnh bên phải → Một chức năng không đơn điệu
Hình ảnh trung bình → Một chức năng đang giảm đơn điệu
Hình ảnh bên phải → Một chức năng không đơn điệu
2.3 Đào tạo mạng lưới thần kinh


Ở đây tôi đã học được sự tồn tại của lan truyền Rprop Back, phương pháp lan truyền ngược này chỉ tính đến dấu hiệu của đạo hàm riêng và không phải là cường độ. Xin vui lòng bấm vào đây nếu bạn muốn đọc về nó nhiều hơn.
3.1 Tại sao phải xây dựng mạng lưới sâu?


Ở đây tôi đã học được lý do chính xác tại sao chúng ta cần sử dụng mạng lưới thần kinh sâu. Có vài điều mà tôi đã học được.
- Về mặt lý thuyết, có thể mô hình hóa bất kỳ chức năng nào chỉ với hai lớp, điều này có nghĩa là chúng ta thực sự không cần phải có một mô hình sâu hơn 2 lớp.
- Nhưng lợi ích của việc sử dụng mạng nơ ron sâu thực sự là hiệu quả của nút. Có thể ước tính các hàm phức tạp với độ chính xác cao hơn khi chúng ta có NN nhỏ hơn nhưng sâu hơn.


Về bản chất, với mạng nơ ron nhỏ hơn và sâu hơn sẽ hiệu quả hơn do lượng công việc dư thừa (theo từng nút) được thực hiện giảm.
3.2 Sinh viên biến mất


Ở đây tôi đã học được ba giải pháp để khắc phục vấn đề độ dốc biến mất. Tôi đã biết về Drop out và ReLU tuy nhiên tôi chưa bao giờ biết rằng chức năng kích hoạt ReLU đã được sử dụng để khắc phục độ dốc biến mất. Và tôi đã không biết về đào tạo trước lớp khôn ngoan.
3.2.1 Giải pháp 1: Đào tạo trước lớp


Ý tưởng này rất thú vị, vì chúng tôi sẽ đào tạo từng lớp đầu tiên theo cách không giám sát và hơn là sử dụng tất cả cùng nhau.
3.2.2 Giải pháp 2: Các đơn vị kích hoạt tuyến tính chỉnh lưu


Mặc dù kích hoạt ReLU () có thể là một vấn đề theo hai cách, kể từ khi
a. Không có đạo hàm tại 0.
b. Không có ràng buộc trong các khu vực tích cực.
Tuy nhiên, nó vẫn có thể được sử dụng vì chúng không làm giảm độ dốc trong khi thực hiện lan truyền ngược (đạo hàm là 1). Tôi không biết rằng lớp kích hoạt ReLU () đã được tạo để khắc phục vấn đề độ dốc biến mất.
b. Không có ràng buộc trong các khu vực tích cực.
Tuy nhiên, nó vẫn có thể được sử dụng vì chúng không làm giảm độ dốc trong khi thực hiện lan truyền ngược (đạo hàm là 1). Tôi không biết rằng lớp kích hoạt ReLU () đã được tạo để khắc phục vấn đề độ dốc biến mất.
3.3 DropOut


Bằng cách loại bỏ các giá trị của các nút nhất định, chúng ta có thể làm cho mỗi nút phát triển độc lập với nhau và điều này làm cho mạng trở nên mạnh mẽ hơn.
3.5 Làm lưới sâu


Ở đây tôi đã học được một phương pháp để cải thiện hiệu suất của một mạng và phương pháp này rất thú vị. Từ tờ giấy Do Do Nets thực sự cần phải sâu? Chúng ta có thể thấy trường hợp một NN sâu được đào tạo để hướng dẫn một mạng lưới nông hơn. Và mạng nông được hướng dẫn này hoạt động tốt hơn mạng nông được đào tạo trực tiếp với dữ liệu đã cho.


Kiến trúc mạng (Mẫu mô tả)
Vì hai mạng kia khá giống nhau từ mạng này, chúng ta hãy thực hiện mạng đầu tiên. Tôi chưa bao giờ thực sự thực hiện phân đoạn với mạng được kết nối đầy đủ, nhưng tôi nghĩ rằng điều này sẽ rất thú vị. Ngoài ra, xin lưu ý do sử dụng tập dữ liệu khác nhau, tôi sẽ thêm một lớp nữa để phù hợp với dữ liệu của chúng tôi. Tuy nhiên, cấu trúc chung của mạng là tương tự nhau.
Vì hai mạng kia khá giống nhau từ mạng này, chúng ta hãy thực hiện mạng đầu tiên. Tôi chưa bao giờ thực sự thực hiện phân đoạn với mạng được kết nối đầy đủ, nhưng tôi nghĩ rằng điều này sẽ rất thú vị. Ngoài ra, xin lưu ý do sử dụng tập dữ liệu khác nhau, tôi sẽ thêm một lớp nữa để phù hợp với dữ liệu của chúng tôi. Tuy nhiên, cấu trúc chung của mạng là tương tự nhau.
Kiến trúc mạng (Mẫu đồ họa)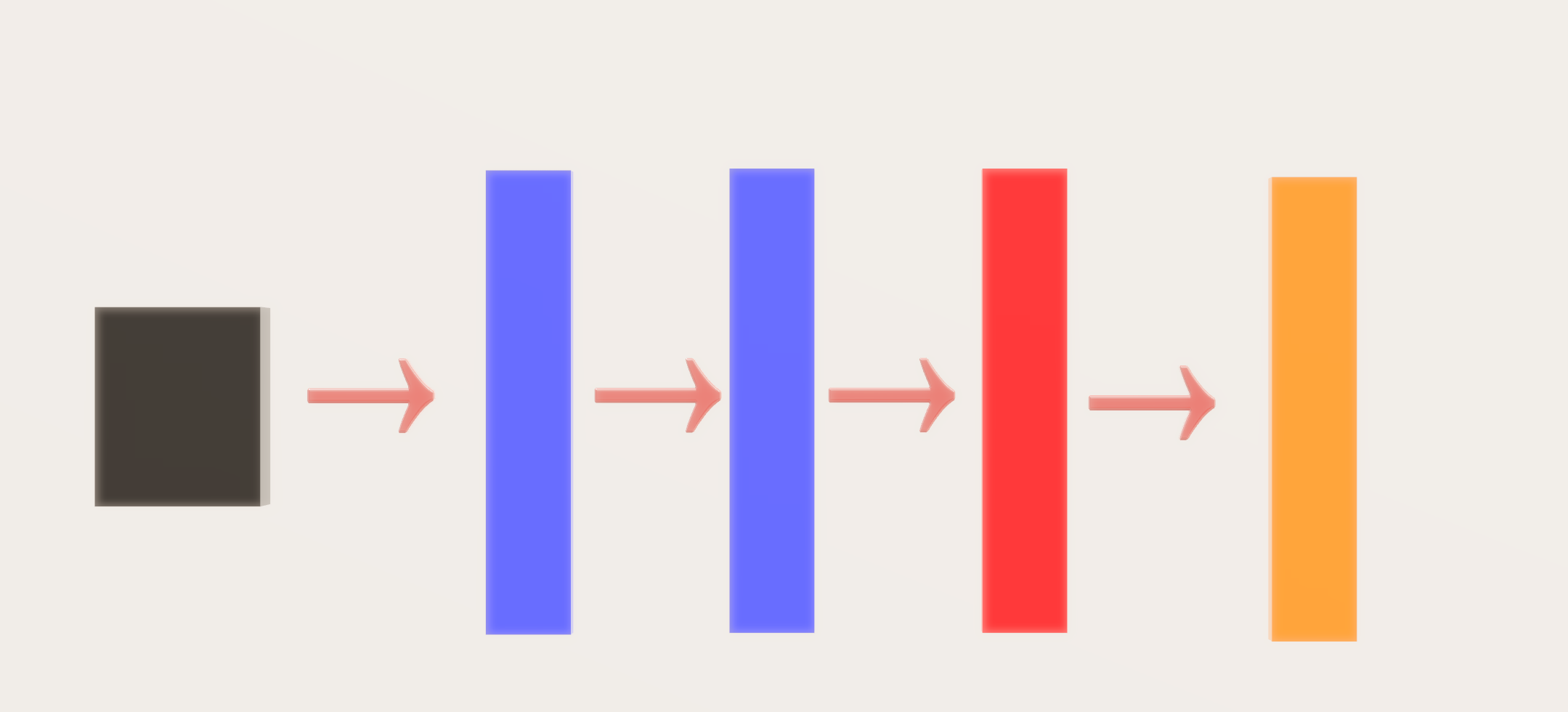
Hình chữ nhật màu đen → Hình ảnh đầu vào Hình
chữ nhật màu xanh → Lớp kết hợp
Hình chữ nhật màu đỏ → Lớp được kết nối đầy đủ (Hình ảnh đầu vào được vector hóa)
Hình chữ nhật màu cam → Lớp tối đa mềm
Hình chữ nhật màu đỏ → Lớp được kết nối đầy đủ (Hình ảnh đầu vào được vector hóa)
Hình chữ nhật màu cam → Lớp tối đa mềm
Mạng tự nó rất đơn giản, bây giờ hãy xem biểu mẫu OOP. Ngoài ra, để khắc phục độ dốc biến mất, hãy sử dụng chức năng kích hoạt ReLU () và kích hoạt tanh () trong lớp được kết nối đầy đủ.
** LƯU Ý ** Do giới hạn phần cứng, tôi đã phải thay đổi một nửa kích thước bộ lọc cho cả hai lớp chập, cũng như kích thước lô (2).
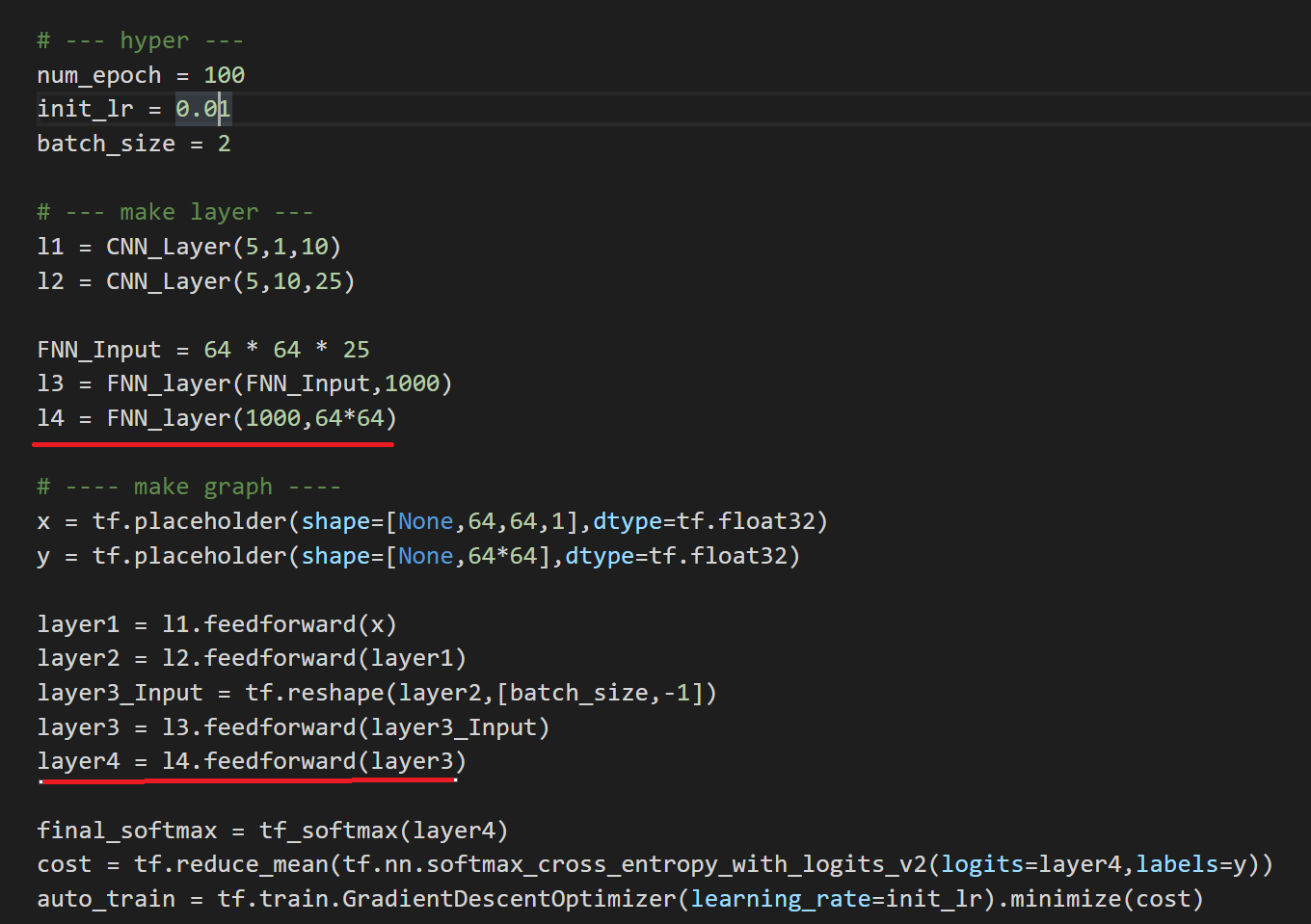
Đường màu đỏ → Đã thêm lớp
Toàn bộ mạng (nhờ độ sâu của nó) có thể được xem trong một lần chụp màn hình. Cuối cùng, chúng ta sẽ sử dụng trình tối ưu hóa giảm dần độ dốc Stochastic.
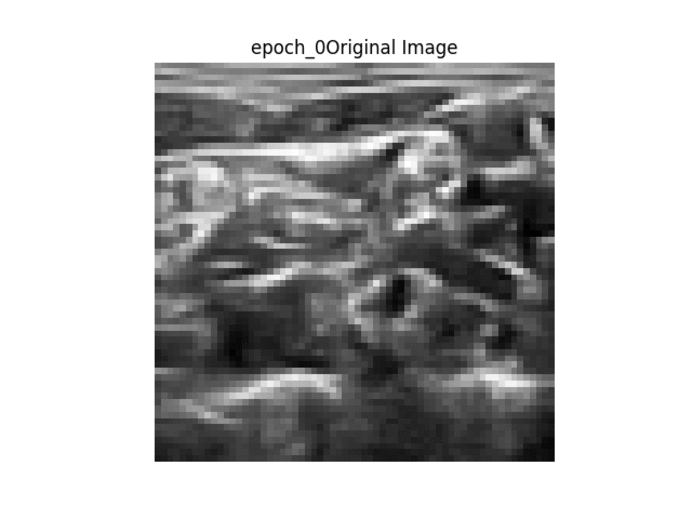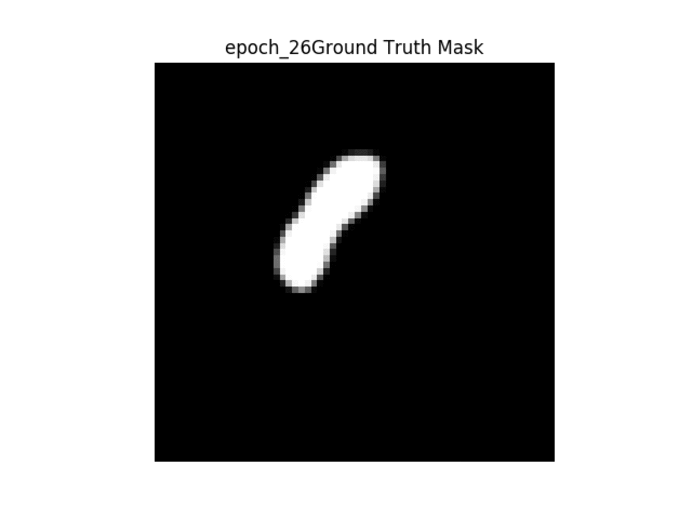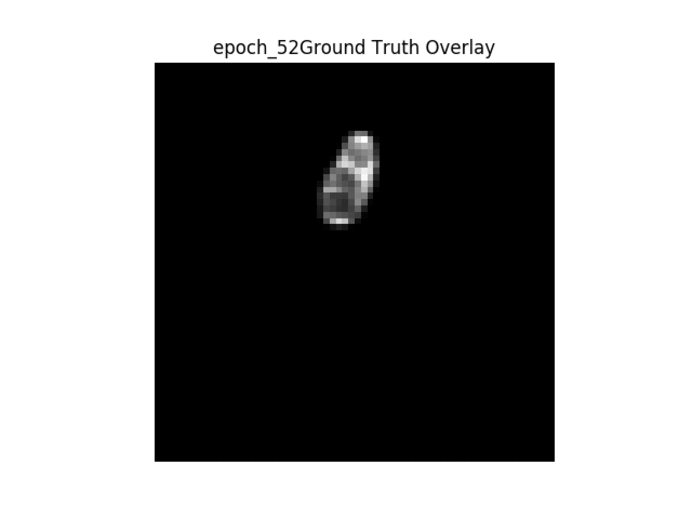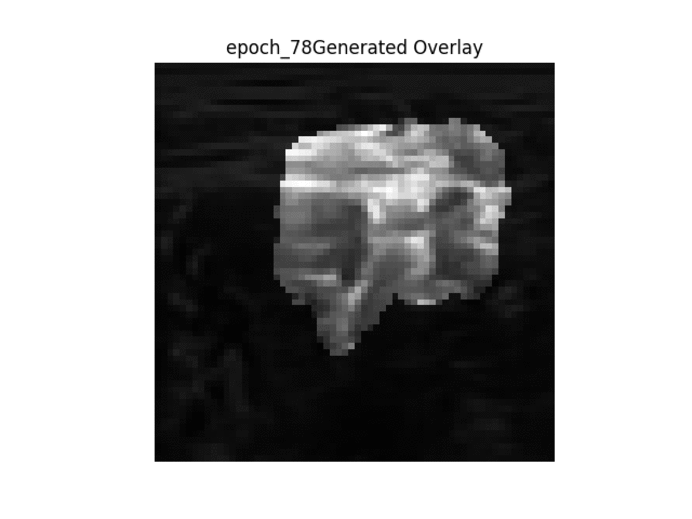
Các kết quả
Hình ảnh bên phải → Hình ảnh gốc Hình ảnh
trung bình → Sự thật mặt đất của mặt nạ nhị phân
Hình ảnh bên trái → Mặt nạ nhị phân được tạo từ mạng
Hình ảnh bên trái → Mặt nạ nhị phân được tạo từ mạng
Mạng cho kết quả kém, tuy nhiên tôi tin rằng điều này là do tập dữ liệu khác nhau mà tôi đã sử dụng. Tôi không có bộ dữ liệu MRI của ADNI Alzheimer để xem, nhưng tôi tin tưởng rằng đầu ra cuối cùng của mạng không phải là phiên bản vector hóa của hình ảnh. Nó có thể tọa độ nơi Hippocampus được đặt vv.
Kết quả trong GIF
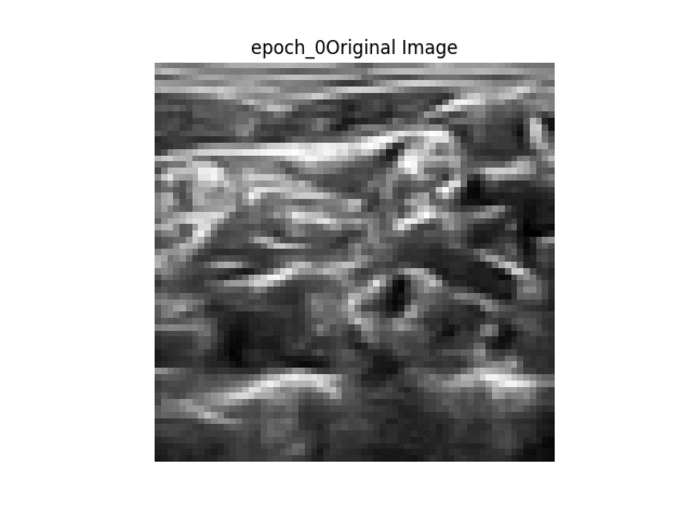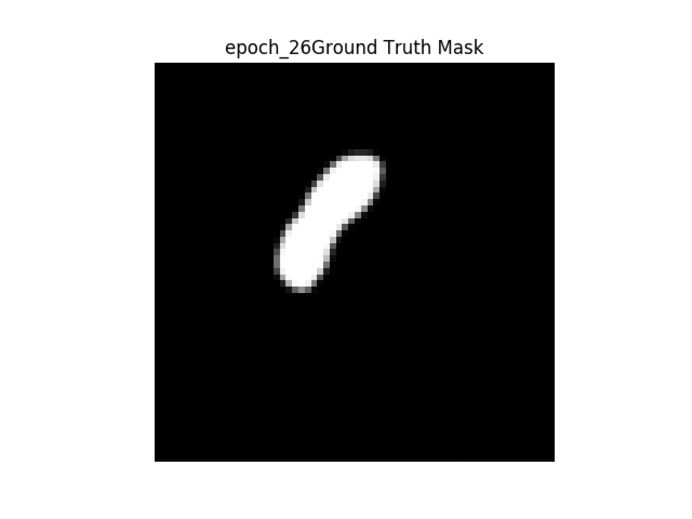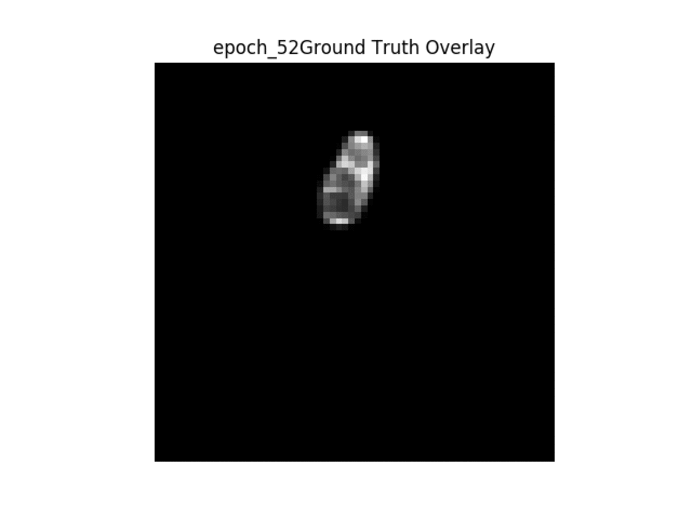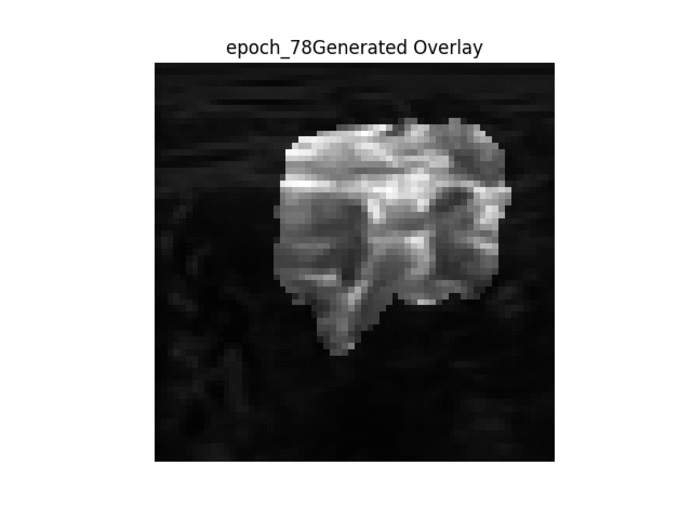
Thứ tự các hình ảnh được trình bày → 1. Hình ảnh gốc → 2. Mặt nạ nhị phân mặt đất → 3. Mặt nạ nhị phân được tạo → 4. Lớp phủ mặt nạ mặt đất trên hình ảnh gốc → 5. Lớp phủ mặt nạ được tạo trên hình ảnh gốc.
Như đã thấy ở trên, khi đào tạo liên tục, chúng ta có thể thấy rằng bộ lọc được tạo trở nên rõ ràng hơn, tuy nhiên mặt nạ được tạo không thay đổi từ hình ảnh này sang hình ảnh khác và thực hiện công việc kém khi phân chia hình ảnh một cách chính xác.
Mã tương tác / Minh bạch
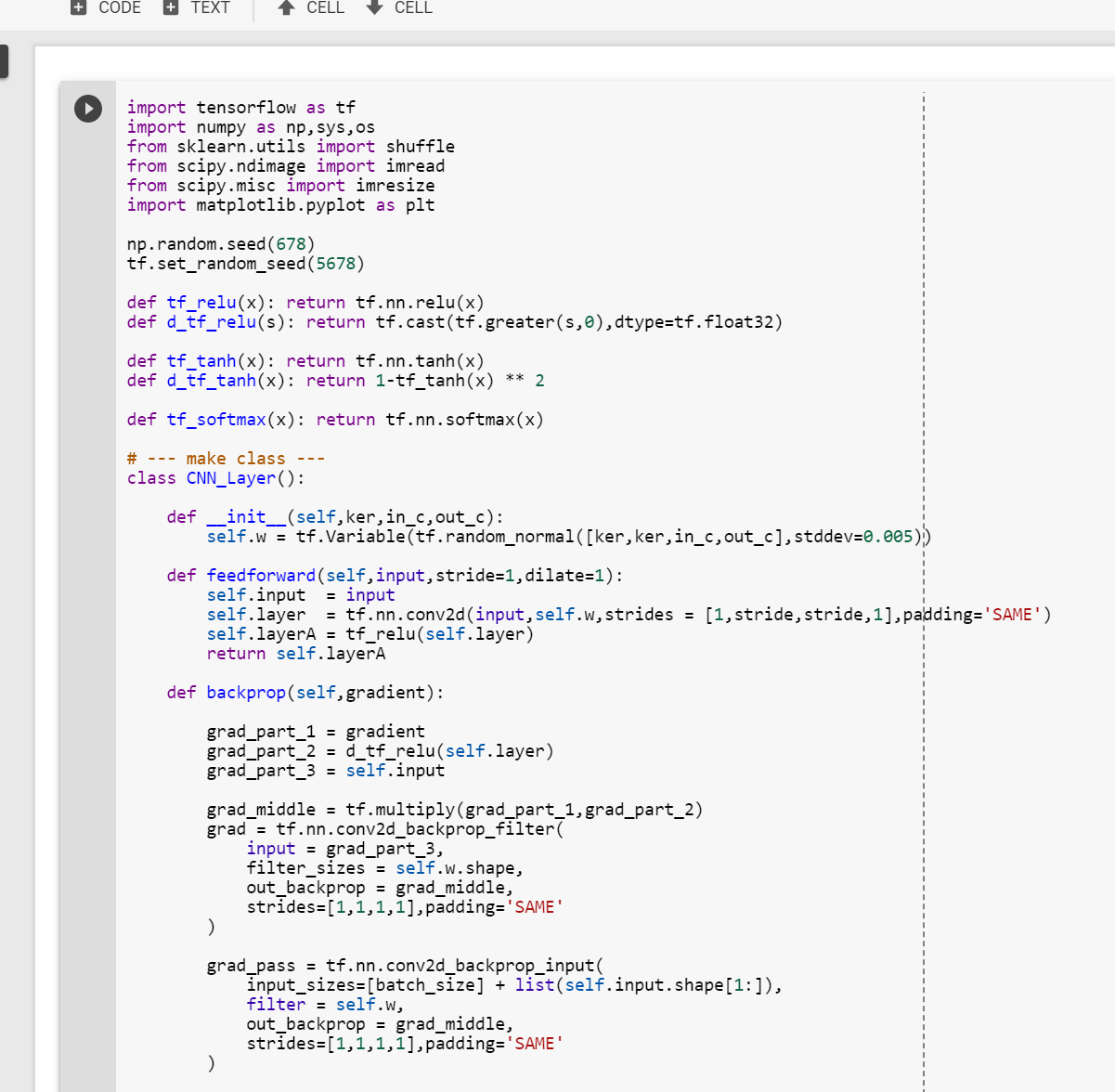
Đối với Google Colab, bạn sẽ cần một tài khoản google để xem mã, ngoài ra bạn không thể chạy các tập lệnh chỉ đọc trong Google Colab để tạo một bản sao trên sân chơi của bạn. Cuối cùng, tôi sẽ không bao giờ xin phép truy cập các tệp của bạn trên Google Drive, chỉ là FYI. Chúc mừng mã hóa!
Để truy cập mã trên Google Colab, vui lòng bấm vào đây.
- * LƯU Ý **: Tôi không muốn lưu trữ Dữ liệu y tế tư nhân trên github của mình, vì tôi có thể phá vỡ chính sách sử dụng dữ liệu của họ. Vì vậy, mã này không thể được chạy trực tuyến.
- Với hy vọng làm cho thử nghiệm này minh bạch hơn, tôi đã tải tất cả đầu ra lệnh của mình lên Github của mình, nếu bạn muốn xem thử, vui lòng bấm vào đây.
Từ cuối cùng
Bài viết dự án tổng thể này được viết một cách xuất sắc cả về tiếng Anh và nội dung, tôi hy vọng sẽ tạo ra nội dung tương tự khi tôi làm chủ.
Nếu có bất kỳ lỗi nào được tìm thấy, xin vui lòng gửi email cho tôi tại jae.duk.seo @ gmail, nếu bạn muốn xem danh sách tất cả các văn bản của tôi xin vui lòng xem trang web của tôi ở đây .
Đồng thời theo dõi tôi trên twitter của tôi ở đây và truy cập trang web của tôi hoặc kênh Youtube của tôi để biết thêm nội dung. Tôi cũng đã so sánh Mạng thần kinh tách rời ở đây nếu bạn quan tâm.
About Công ty TNHH TMDV Công Nghệ TK





Không có nhận xét nào